
티스토리 뷰
사진에 들어있는 텍스트를 컴퓨터로 인식하는 것 (OCR: Optical Character Recognition) 은 컴퓨터 비전의 한 분야로서 예전부터 꾸준히 연구되어왔던 분야인데, 요즘은 머신러닝 기술이 발전하면서 예전보다 훨씬 높은 인식률을 구현할 수 있게 된 것 같다. 특히 뉴럴 네트워크의 한 종류인 CNN (Convolutional Neural Network) 이 이미지 인식에 많이 사용되는 기술이라고 알고 있다.
하지만 이런 머신러닝 기술을 직접 로우레벨부터 구현하기엔 많은 노력이 필요하다. 뉴럴 네트워크를 구축하고 데이터를 모아서 학습을 시키고 파라미터를 조절하고... 이런걸 OCR을 이용한 서비스 하나 만들어보겠다고 다 배우는 것보다 편리한 방법은 클라우드 서비스를 이용하는 것이다. AWS나 Google 등 주요 클라우드 프로바이더들은 머신러닝을 쉽게 내 서비스에서 적용할 수 있도록 API를 제공한다. 물론 클라우드이니만큼 API를 사용한 만큼 요금을 지불해야 한다.
이 포스팅에서는 Google에서 제공하는 Vision API를 이용해서 이미지의 텍스트를 인식하는 기본적인 예제에 대해서 알아본다. 언어는 Java를 이용하기로 하고, 이클립스에서 Maven Project를 만들어서 jsp 파일로 테스트를 했다.
1) API 사용 준비
- 구글 클라우드 콘솔에 접속, 프로젝트를 만들고 결제 수단을 세팅한다.
- APIs & Services 탭으로 가서 Enable APIs And Services 버튼을 클릭하여 'Vision API' 를 찾아 Enable 시킨다.
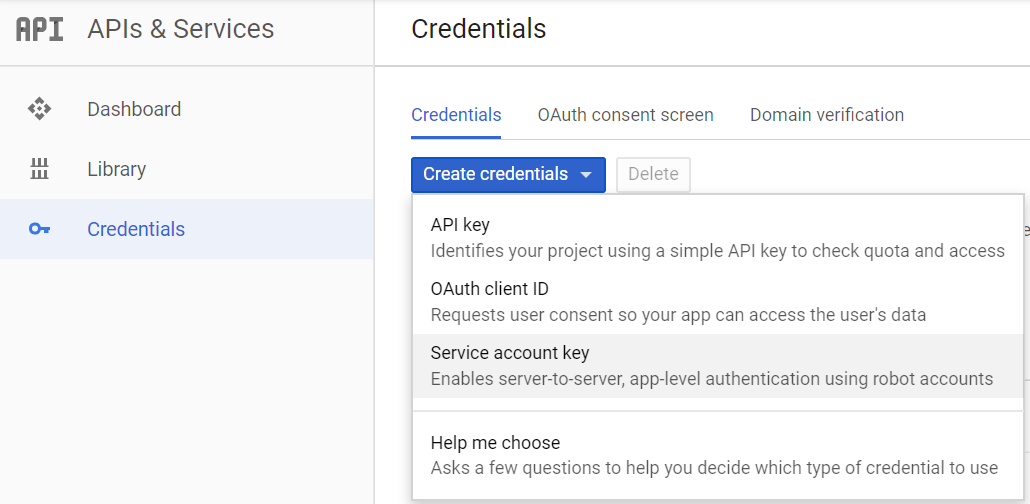
- APIs & Services 탭의 하위 탭 중 Credentials 파트로 가서 Create credentials 버튼을 클릭하고 Service account key를 선택한다. Key Type을 JSON으로 선택하고 확인을 누르면 JSON 파일을 자동으로 다운로드받는데 이 파일을 가지고 있다가 나중에 인증 수단으로 쓰면 된다.
> 이 JSON 파일은 처음 키를 생성할 때 한번만 다운받을 수 있게 되어있다. 삭제했거나 어디 박아놨다가 까먹었을 경우 키를 다시 생성해야 한다.
> Service account key가 아니라 OAuth client ID를 선택해도 뭔가 생성되면서 JSON 파일을 다운로드받을 수 있는데, 이 JSON 파일이랑 위의 JSON 파일은 둘 다 인증용 JSON 파일이긴 하지만 세부 형식이 다르기 때문에 여기선 이걸 쓰면 안된다. 다른 라이브러리를 쓸 때는 OAuth client ID를 쓰는 경우도 있었는데 둘의 차이점에 대해서는 좀 더 알아봐야 할 것 같다.
2) 라이브러리 Import 및 환경 변수 설정
API를 사용하기 위해 콘솔에서 해줘야 하는 사전 작업을 마쳤다면, 라이브러리를 다운로드받아서 Import할 차례다. 여느 자바 라이브러리가 그렇듯 방법은 크게 두 가지가 있다.
- .jar 파일을 직접 다운로드받아서 라이브러리 경로 폴더에 넣는다.
최신 버전 문서에는 어째 .jar 파일을 바로 다운로드받는 링크가 안 보이더라. 예전 버전은 여기서 다운받을 수 있는 것 같다.
- Maven이나 Gradle 같은 빌드 도구를 사용한다면 xml 파일에 라이브러리에 대한 의존성을 추가해준다.
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-vision</artifactId>
<version>1.61.0</version>
</dependency>
이런 클라우드 라이브러리들은 Import만 한다고 바로 사용할 수 있는게 아니라 인증 과정을 거치게 되어있다. 위에서 받아놨던 JSON 파일을 인증 수단으로 사용해야 하는데, 이클립스에서는 실행 환경에 따른 환경 변수를 세팅할 수 있는 기능이 있고 이 기능을 이용해 인증을 위한 환경 변수를 추가해주면 된다.

실행하게 될 jsp 파일을 우클릭 후 Run Configuration 메뉴로 들어가면 이런 창이 뜨는데, 실행할 환경 (예시에서는 톰캣 서버) 을 선택하고 Environment 탭으로 들어가서 'GOOGLE_APPLICATION_CREDENTIALS' 라는 이름으로 환경 변수를 추가해준다. 값은 아까 받아놨던 JSON 파일의 경로 (JSON 파일이 들어있는 폴더가 아니라 JSON 파일 이름까지 풀로 써줘야 한다) 를 입력해주면 된다.
3) API 사용하기
JSP 파일이며 자바 코드에 대한 간단한 설명은 주석으로 달았다.
<html>
<body>
<%@ page contentType="text/html; charset=utf-8" %>
<%@ page import="com.google.cloud.vision.v1.ImageAnnotatorClient" %>
<%@ page import="com.google.cloud.vision.v1.AnnotateImageRequest" %>
<%@ page import="com.google.cloud.vision.v1.AnnotateImageResponse" %>
<%@ page import="com.google.cloud.vision.v1.BatchAnnotateImagesResponse" %>
<%@ page import="com.google.cloud.vision.v1.Feature" %>
<%@ page import="com.google.cloud.vision.v1.Feature.Type" %>
<%@ page import="com.google.cloud.vision.v1.EntityAnnotation" %>
<%@ page import="com.google.cloud.vision.v1.Image" %>
<%@ page import="com.google.protobuf.ByteString" %>
<%@ page import="java.io.FileInputStream" %>
<%@ page import="java.util.ArrayList" %>
<%@ page import="java.util.List" %>
<%
// 이미지 파일을 읽는 부분이다. FileInputStream은 자바 자체의 기능이지만 ByteString이라는 타입은 구글 API에서 제공하는 것 같고 이 형식으로 이미지를 읽는다.
String imageFilePath = "이미지파일경로\\test.jpg";
ByteString imgBytes = ByteString.readFrom(new FileInputStream(imageFilePath));
// 서버로 분석 요청을 보내기 위해 AnnotateImageRequest라는 객체를 생성하는 부분이다. ArrayList로 만든건 여러개의 이미지를 한번의 요청으로 처리할 수도 있어서 그런 것 같지만 예제에서는 1개의 이미지 파일이니 큰 의미 없다.
// TEXT_DETECTION은 일반적인 사진에서 이미지를 추출하기 위한 타입이고 다른 타입도 있다. 예를 들어 DOCUMENT_TEXT_DETECTION으로 바꿔주면 책처럼 밀집된 문서에 더 알맞도록 최적화된다.
List<AnnotateImageRequest> requests = new ArrayList<>();
Image img = Image.newBuilder().setContent(imgBytes).build();
Feature feat = Feature.newBuilder().setType(Type.TEXT_DETECTION).build();
AnnotateImageRequest req = AnnotateImageRequest.newBuilder().addFeatures(feat).setImage(img).build();
requests.add(req);
// 만들어진 AnnotateImageRequest를 클라이언트 요청에 담아 보내서 Response 객체를 받아오는 부분이다.
try (ImageAnnotatorClient client = ImageAnnotatorClient.create()) {
BatchAnnotateImagesResponse resp = client.batchAnnotateImages(requests);
List<AnnotateImageResponse> responses = resp.getResponsesList();
// 1개의 이미지만 넣었기 때문에 response도 하나이고, 따라서 for문은 별 의미는 없다.
for (AnnotateImageResponse res : responses) {
if (res.hasError()) {
out.println(res.getError().getMessage());
return;
}
// Response 객체에 담겨져 온 분석 결과 (이미지 내의 텍스트) 가 여기서 출력된다.
out.println("Text : ");
out.println(res.getTextAnnotationsList().get(0).getDescription());
}
} catch(Exception e) {
e.printStackTrace();
}
%>

예시 이미지로 이걸 (팝픈뮤직 리절트 사진) 써서 위의 프로그램을 돌려본 결과는 아래와 같다.

뭔가 순서도 뒤죽박죽인 것 같고 폰트 때문에 SCORE가 SOORE로 인식되는 등 문제가 있긴 하지만 점수랑 각 판정이 몇개씩 나왔는지는 제대로 뽑아내고 있다. 물론 이 뒤죽박죽 데이터를 파싱해서 필요한 데이터만 뽑아내는 작업이 더 필요하겠지만, 리절트 사진으로부터 점수나 판정 데이터를 추출해서 기록을 관리하는 프로그램 같은 걸 만들 수도 있겠다.
위의 예시에서는 단순히 텍스트만 가져왔지만 각 텍스트의 이미지상 좌표 같은 추가적인 정보도 확인할 수 있다. 위의 코드에서
res.getTextAnnotationsList().get(0).getDescription();
뒤의 취소선 부분을 빼면 EntityAnnotation 객체를 얻는데, 이 EntityAnnotation 객체의 메서드 중 getBoundingPoly() 라는 메서드를 쓰면 인식한 텍스트에 대해 그 텍스트를 인식한 위치를 사각형으로 (사각형의 각 꼭지점 좌표로) 알려준다.
for (EntityAnnotation annotation : res.getTextAnnotationsList()) {
System.out.printf("Text: %s\n", annotation.getDescription()); // 인식한 텍스트를 인식 단위 (단어?) 별로 출력
System.out.printf("Position : %s\n", annotation.getBoundingPoly()); // 해당 인식 단위에 대한 좌표 출력
}