
티스토리 뷰
이전 포스팅에서 머신 러닝의 기본 개념과 가장 기본적인 Decision Tree 분류 알고리즘에 대해서 얘기했었는데, 이번 포스팅에서는 weka라는 툴을 이용해서 이걸 실제로 돌려보고 간단한 테스트 프로그램을 만들어 본다.

weka는 뉴질랜드 Waikato 대학교에서 제작한 머신 러닝 툴이다. 'Waikato Environment for Knowledge Analysis' 의 약자이며 위 사진처럼 생긴 귀여운 뉴질랜드 고유종 새 이름이기도 하다.
weka는 Java로 만들어졌으며 여러 가지 기능을 제공한다. weka explorer라고 해서 트레이닝 데이터랑 알고리즘을 선택해서 머신 러닝 시뮬레이션을 해볼 수 있는 GUI를 제공하며, 이걸 내가 만든 프로그램에 적용해서 써먹을 수 있도록 Java 라이브러리도 제공한다.
설치는 weka 공식 홈페이지에서 할 수 있다. 자바 프로그램이기에 JRE가 설치되어 있어야 하며, 다운로드 옵션에서 JRE가 포함된 버전이랑 포함되지 않은 버전 중에 골라서 받을 수 있다. 글쓰는 시점 (2019/05) 기준으로 Stable 버전은 3.8, 개발중 버전은 3.9이다.

weka를 설치하고 실행해보면 이런 창이 제일 먼저 뜬다. 5개의 메뉴 중에 선택할 수 있는데 나는 Explorer밖에 안 써봤고 포스팅에서는 Explorer만 설명할 것이다. 그래도 다른게 뭔지 정도는 알고 싶으니 문서를 좀 찾아봤다. 각 메뉴의 기능은 다음과 같다.
- Explorer: 가장 기본적인 환경으로 데이터를 넣어 전처리 및 학습을 시키고 결과를 볼 수 있는 환경이다.
- Experimenter: 학습 계획간에 실험 및 통계적 테스트를 수행하게 해주는 환경이다. (?)
- KnowledgeFlow: 기본적으로 Explorer와 같은 기능을 제공하나, drag-and-drop 형식의 인터페이스를 제공하며 Incremental Learning (데이터를 순차적으로 넣어 다단계로 학습하는 기법) 을 지원한다.
- Workbench: 위의 다른 메뉴들의 기능을 모두 담았고 사용자가 perspective 형식으로 나눠서 볼 수 있다.
- Simple CLI: 말 그대로 GUI가 아닌 커맨드라인 인터페이스로 weka 커맨드를 실행할 수 있는 환경이다.
읽어보면 결국 Experimenter를 제외하고 기본적인 뼈대 기능은 다 Explorer로 할 수 있다는 소리인 것 같다.
Explorer를 눌러보면 아래와 같은 창이 뜬다.
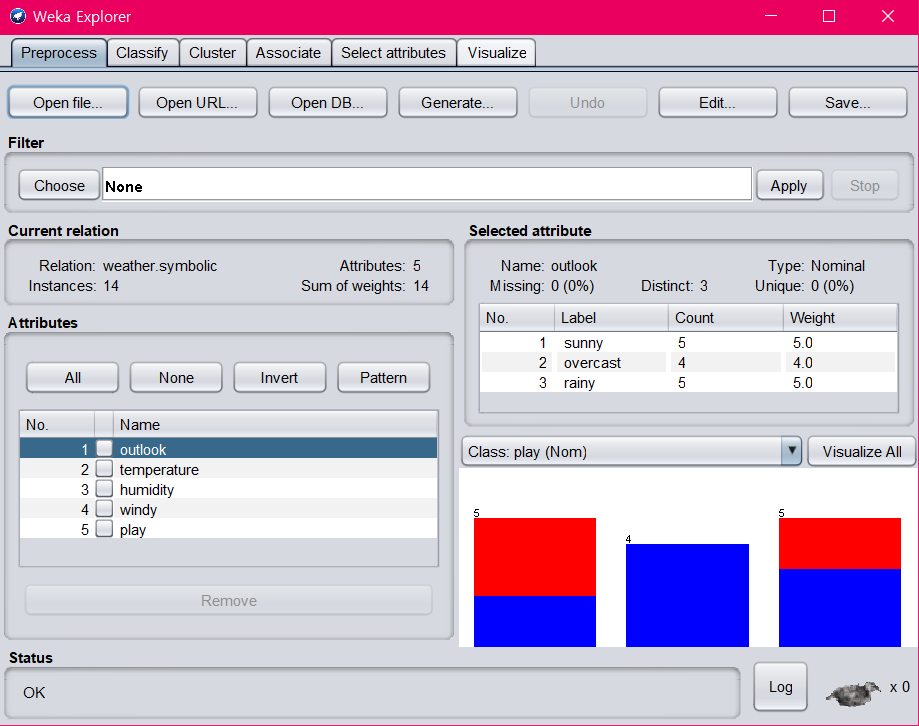
지난 포스팅을 읽었다면 익숙한 데이터가 보일 것이다. 이 데이터는 어디서 갖고왔냐면 왼쪽 위의 'Open file...' 을 누른 다음 weka 설치 경로 -> data 폴더로 들어가면 'weather.nominal.arff' 라는 파일이 있다 (arff는 weka에서 쓰이는 데이터 포맷이다). 그걸 열면 위 화면처럼 뜬다.
왼쪽 하단에는 Attributes (지난 포스팅에서는 Feature라는 용어를 썼었는데 같은 의미다) 들이 있는데, play도 끼어 있다. 위의 4개를 가지고 play를 판별하는 거였는데 왜 Attributes에 play가 있냐고 할 수 있지만 임의의 데이터 파일을 줬을 때 판별할 속성이 뭔지는 데이터 파일 자체에 들어있는게 아니기 때문에 그렇다. 판별할 대상 속성이 play라는건 오른쪽에 보이는 드롭다운 박스로 선택해주면 된다. 'Class: play (Nom)' 라고 선택되어 있는걸 볼 수 있다.
그 위에는 선택된 Attribute가 가지는 값들 (Label) 과 각각의 개수 (Count) 가 표시되어 있다. 'Type: Nominal' 이라고 되어있는 것은 이 Attribute의 값들이 이산적이라는 의미다. 연속적인 숫자 값인 경우 Numeric이라고 뜬다. Missing Data가 있을 경우 그 수도 표시된다.
여기까지는 불러온 데이터가 어떻게 생겼는지 그냥 보는 기능이다. 근데 위쪽을 잘 보면 이 탭의 이름이 'Preprocess' 라고 되어 있다. 뭘 전처리한다는 걸까? 메뉴 아래쪽을 보면 Filter라는 기능이 있는데 이것이 데이터 전처리를 위한 기능이다. Choose 버튼을 누르면 아래와 같은 화면이 뜬다.

Filter라는 것은 데이터에다가 어떠한 처리를 가하는 함수 같은 것인데, 예를 들면 진하게 표시되어 있는 'Discretize' 라는 필터를 적용하면 Numeric 타입의 데이터가 Nominal 타입으로 바뀐다. Decision Tree 얘기할 때 Attribute의 값이 연속적인 숫자값 (Numeric) 이면 처리하기가 힘들기 때문에 적당한 범위로 묶어주는게 좋다고 했는데 그 처리를 해주는게 이 Discretize 필터다. 또 유용한 걸로 AttributeSelection이라는 필터가 있는데, Attribute의 수가 많을 경우 그걸 다 학습에 반영하는 건 비효율적일 수도 있으므로 Attribute들 간의 관계성을 분석해서 쓸모있을 법한 Attribute만 추려내는 알고리즘이다.
이러한 필터를 잘 활용해서 데이터를 정제하면 학습 시 더 좋은 성능을 나타낼 수 있다.
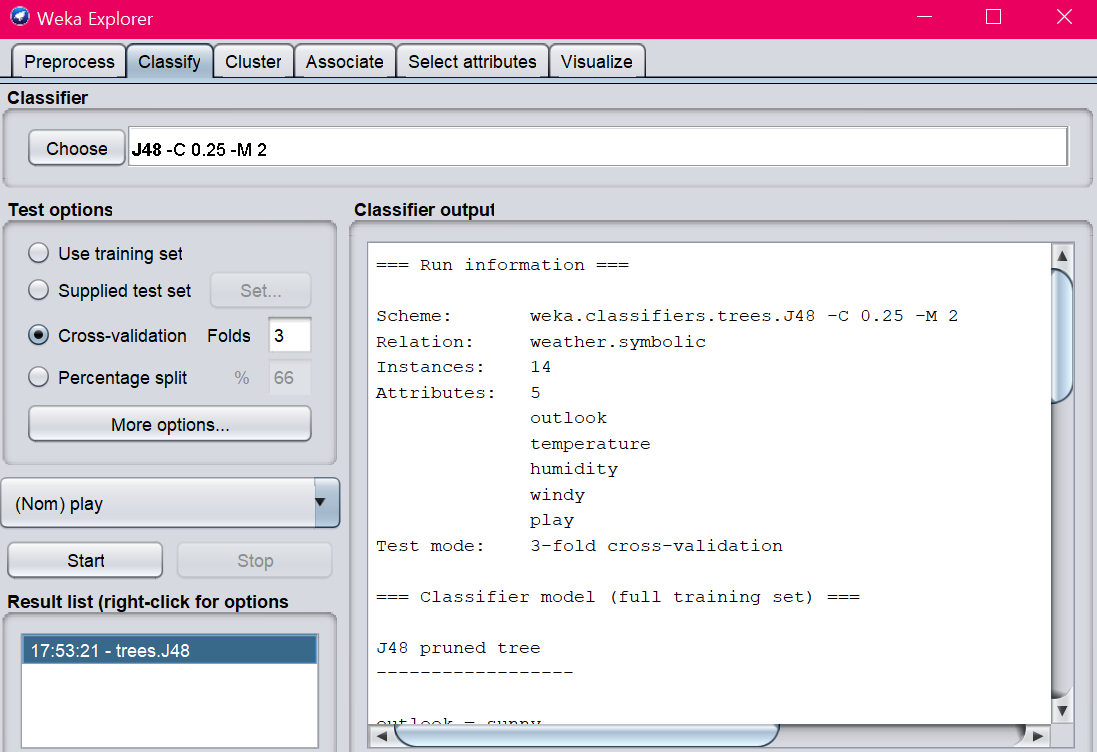
다음 탭인 Classify 탭으로 가보자. 앞의 Preprocess 탭에서 불러왔던 데이터를 이용해서 학습 모델을 만들고, 테스트를 통해 성능을 평가할 수 있는 부분이다.
'Classifier' 에서 분류 알고리즘을 선택하게 되는데, Decision Tree 말고도 분류에 쓸 수 있는 여러 알고리즘들이 카테고리별로 들어있다. 'tree' 카테고리로 들어가면 Decision Tree 계열의 알고리즘들이 있는데, 그냥 Decision Tree라고 써있는건 없다. Decision Tree도 세부적으로 여러 이름이 붙은 알고리즘들이 존재하기 때문인데, 들어있는 것들 중 가장 일반적인 아이는 J48이다. 이걸 골라보자.
고르고 나면 Classifier에 J48이라 뜨고 옆에 몇 가지 파라미터들이 뜨는데, 저 흰색 박스를 클릭하면 파라미터를 조절할 수 있는 창이 뜬다. 파라미터 세팅에 따라서 학습 모델의 성능이 달라지기도 하며, 굳이 Decision Tree나 분류 문제 뿐 아니라 저런 파라미터들을 어떻게 설정하는게 좋은가 하는 문제는 여전히 어려운 문제고 계속 연구가 이루어지고 있다. 일반론적인 답이 없기 때문에 파라미터는 보통 실험적으로 결정하는 모양이다. 그러니까 좋은 결과가 나올때까지 파라미터를 계속 바꿔가면서 노가다를 해본다는 얘기다... 여기서는 일단 기본 세팅 그대로 두자.
그 아래를 보면 Test options라는 부분이 있는데 만들어진 학습 모델에 어떤 데이터를 넣어서 성능을 평가할 것인지를 정하는 부분이다. 그냥 Training Set을 그대로 넣을 수도 있고, 특정한 Test Set을 지정해서 넣어줄 수도 있다 (Set... 버튼을 누르면 데이터 파일을 가져올 수 있다). 이전 포스팅에서 설명했던 k-fold Cross Validation도 지원하며, Percentage Split이라고 해서 데이터의 일정 비율만큼을 Training Set으로, 나머지는 Test Set으로 쓰는 방법도 있다 (Cross Validation하곤 다르게 Test Set을 바꿔가면서 하지는 않고 1번만 테스트를 수행한다).
그 밑에 있는 드롭다운 박스는 앞에서 봤던 거랑 똑같이 판별할 속성이 뭔지 고르는 것이다. play를 고른다.
Start 버튼을 누르면 학습이 시작되고, 완료되면 오른쪽에는 Training에 사용된 데이터의 인스턴스 (항목) 개수, Attribute 개수, 만들어진 트리의 사이즈, 학습에 걸린 시간, Accuracy/Precision/Recall 및 기타 평가 척도, Confusion Matrix 등이 정리되어 나타난다.
왼쪽 아래에 있는 'Result list' 에서 이번에 실행한 항목을 오른쪽 클릭하고, 'Visualize Tree' 를 누르면 아래 그림과 같이 만들어진 Decision Tree를 Graphical하게 확인할 수 있다.
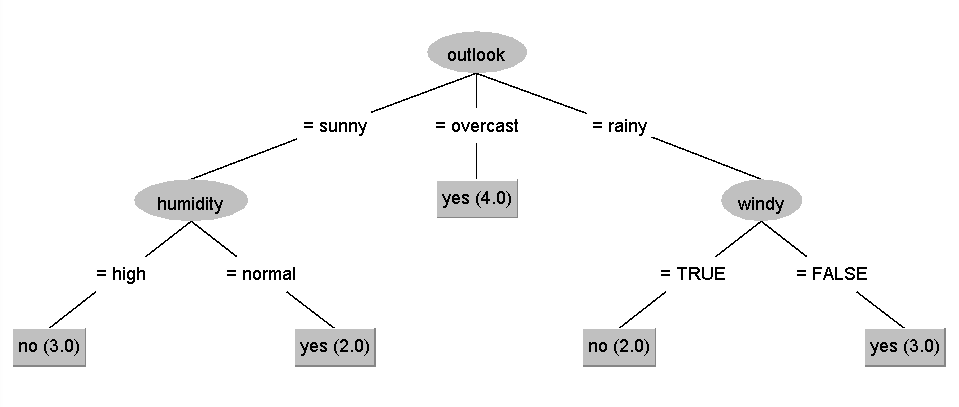
이전 포스팅에서 봤던 트리와 동일하다.
학습 모델을 만들고 테스트까진 해봤는데, 이걸 내 프로그램에 적용해보고 싶다. 그런 우리를 위해 weka는 자바 라이브러리, 그러니까 API를 제공한다. 여기로 가면 문서를 볼 수 있다.
weka가 설치된 폴더로 가면 weka.jar이라는 파일이 있다. 이걸 import해주면 weka API를 사용할 수 있다.
간단한 예제 프로그램을 하나 보면서 어떤 식으로 쓰는건지 알아보자.
import java.io.*;
import java.util.*;
import weka.classifiers.*;
import weka.classifiers.trees.*;
import weka.core.Instances;
public class weka_test {
public static void main(String[] args) throws Exception {
// 트레이닝 데이터 정보 불러오기
Instances training_data = new Instances(new BufferedReader(
new FileReader("D:\\weka-3-8\\data\\weather.nominal.arff")));
training_data.setClassIndex(training_data.numAttributes() - 1); // n번째 속성을 클래스로 설정
// 테스트 데이터 정보 불러오기
Instances testing_data = new Instances(new BufferedReader(
new FileReader("D:\\weka-3-8\\data\\weather_test.arff")));
testing_data.setClassIndex(testing_data.numAttributes() - 1);
Classifier tree_c = new J48(); // J48 Decision Tree 분류기를 선택
tree_c.buildClassifier(training_data);
double prob_class0 = 0;
double prob_class1 = 0;
// 테스트 데이터에 대하여
for (int i = 0; i < testing_data.numInstances(); i++) {
double pred = tree_c.classifyInstance(testing_data.instance(i));
System.out.print("Test Data " + i + " --- ");
System.out.print("given value: " + testing_data.classAttribute().value(
(int) testing_data.instance(i).classValue()));
System.out.println(". predicted value: "
+ testing_data.classAttribute().value((int) pred)); // 분류 결과 (yes 또는 no)
double[] prediction = tree_c.distributionForInstance(testing_data.get(i)); // yes 또는 no로 분류될 확률
prob_class0 = prediction[0];
prob_class1 = prediction[1];
System.out.println(prob_class0);
System.out.println(prob_class1);
'Instances' 라는 데이터 타입은 weka에서 다룰 데이터, 즉 학습에 쓰일 트레이닝 데이터나 분류할 테스트 데이터를 표현한다. 생성자의 파라미터로 arff 파일을 넣어주면 arff 파일로부터 데이터를 가져올 수 있다. 즉 'training_data' 변수에는 위에서 봤던 날씨 데이터가 쭉 들어간다.
이 데이터를 가지고 위에서 했던 것처럼 Decision Tree를 만든 다음, 아래의 새로운 데이터를 분류해 보자.
Outlook=Sunny, Temp=Cool, Humidity=High, Wind=TRUE
트레이닝 데이터 파일은 weka에서 기본적으로 제공하는 arff 파일을 썼지만, 이 새로운 데이터에 대한 파일은 우리가 만들어줘야 한다. weather_test.arff 파일은 이렇게 생겼다.
@relation weather.symbolic
@attribute outlook {sunny, overcast, rainy}
@attribute temperature {hot, mild, cool}
@attribute humidity {high, normal}
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,cool,high,TRUE,no
직관적인 데이터 형식이다. @data 위까지는 'weather.nominal.arff' 파일에서 그대로 긁어오면 되고, @data 밑에 분류하기로 한 데이터를 넣어주면 된다. 각 attribute는 콤마로 구분한다.
얘는 분류 대상이기 때문에 마지막에 'no' 를 넣어줄 필요가 없다고 생각할 수도 있는데, 그러면 에러가 난다. 그러니 yes든 no든 일단 적당히 넣어준다.
그 다음에 Classifier 객체를 만들고 buildClassifier() 함수에 training data를 넣어주면 학습을 진행한다.
for문 이후의 부분은 만들어진 Decision Tree를 이용해서 테스트 데이터를 분류하고, 그 결과를 콘솔 화면에 뿌려주는 부분이다. classifyInstance() 함수는 이름 그대로 데이터를 해당 학습 모델을 이용해서 분류하는 함수인데, return 타입이 double이다. 이 예제에서는 arff 파일에 정의된 순서에 따라서 0은 yes, 1은 no를 의미하게 되며 이를 yes/no로 바꿔서 보여주기 위해 아래 print 부분에서 classAttribute().value() 함수를 쓰고 있다.
그 밑에 distributionForInstance() 라는 함수도 있는데 이 함수는 yes나 no로 분류될 확률 분포를 뽑아준다. Decision Tree는 확률 기반 알고리즘이 아니기 때문에 사실 이 함수를 쓸 필요가 없다 (0 아니면 1로만 뜬다). 그렇지만 Naive Bayes같은 확률 기반 알고리즘에서는 yes일 확률이 얼마, no일 확률이 얼마 이렇게 계산해서 더 확률이 높은 쪽으로 분류하게 되는데 이 때 이 함수를 이용하면 그 세부 확률을 볼 수가 있다.

위 프로그램의 실행 결과 출력 화면이다. given value는 weather_test.arff 파일에서 임시로 넣어줬던 값이고, predicted value가 Decision Tree에 의해 예측된 분류 결과이다.

위 사진은 Naive Bayes 알고리즘을 이용해 분류한 결과이다. 위의 프로그램에서 Classifier만 J48 대신 NaiveBayes로 바꿔주면 되는데, 사진에서 볼 수 있듯 yes일 확률과 no일 확률을 각각 계산한 다음 no로 분류될 확률이 더 높으니까 no로 분류하였다.