
티스토리 뷰
1. 상호배타집합 (Disjoint Set) 이란?
서로 중복으로 포함된 원소가 없는 집합들을 상호배타집합, 또는 서로소 집합이라 부른다.
즉 집합들간에 교집합이 없다는 의미이다.
ex)
집합 A = {1, 2}, B = {3, 4} 는 Disjoint Set이다.
집합 A = {1, 2}, B = {2, 4} 는 Disjoint Set이 아니다. 2가 중복으로 들어가있기 때문이다.
그래프 문제를 비롯해서 알고리즘 문제를 풀다보면, 문제에서 주어지는 여러 개체를 집합으로 묶고, 그 집합들을 합친다던지 어떤 개체가 어떤 집합에 들어가있는지 찾는다던지 하는 일을 해야하는 경우가 종종 있다.
이 때 주어지는 개체들이 중복된 값을 가지지 않는 별개의 개체들이라면, 만들어지는 집합은 Disjoint Set이라 할 수 있다. 그리고 이런 문제를 풀 때 사용되는 알고리즘을 주요 연산의 이름에서 따와 Union-find 알고리즘이라 부른다.
Union-find 알고리즘은 그냥 단독으로 쓰이는 경우는 별로 없지만, 다른 알고리즘을 구현하기 위한 중간 과정으로 많이 사용되기 때문에 알아두면 유용한 알고리즘이라 한다.
대표적으로 최소비용 신장트리 (MST) 를 만드는 크루스칼 알고리즘이 Union-find 알고리즘을 이용한다.
본 포스팅에서는 Union-find 알고리즘에 대해 소개한다.
2. Union-find 알고리즘의 연산들
Union-find 알고리즘에서 사용되는, Disjoint Set을 다루는 연산들로는 아래와 같은 3가지가 있다.
1) Make-Set(x)
x라는 원소 하나를 이용해 크기 1짜리 집합을 만든다. 즉 이 집합에는 x라는 원소 하나만 들어있게 되며, 자기 자신이 집합의 '대표자' (representative) 가 된다.
대표자란, 각 집합마다 1개씩 있는, Union-find 알고리즘에서 집합을 구분하는 데 사용되는 원소를 의미한다.
2) Find-Set(x)
x라는 원소의 대표자를 찾는다.
예를 들어서 {1, 2, 3, 4} 라는 집합이 있고 1이 대표자라면, Find-Set(4) = 1이다.
직관적으로 생각하면 'x라는 원소가 몇번 집합에 들어있는지?' 같은 걸 찾아줘야 할 것 같지만, Union-find 알고리즘에서는 사실 집합을 위한 별도의 공간을 생각하지 않는다. 대표자가 같으면 같은 집합에 속해있는 것이고, 대표자가 다르면 다른 집합에 속해있는 것이다.
3) Union(x, y)
x, y 두 원소가 속해있는 집합을 합친다.
중요한 것은 x, y라는 원소들을 합치는게 아니라 그들이 속해있는 '집합' 끼리 합친다는 것이다. Union-find 알고리즘에서는 집합을 구분하기 위해 '대표자' 를 이용한다고 했다. 그래서 x, y가 각각 속해있는 집합의 대표자를 찾아야 하며, 이 과정에서 Find-Set(x), Find-Set(y) 가 이용된다.
두 집합의 대표자가 같다면 이미 같은 집합에 속해있는 것이기 때문에 Union을 할 수가 없고, 무효가 된다.
두 집합의 대표자가 다르다면 두 집합을 합쳐줘야 하는데, 두 집합을 합친다는 것은 곧 하나의 집합이 된다는 것이며, 하나의 집합에 대표자는 1개만 존재할 수 있으므로 두 대표자 중에 하나는 대표자 딱지를 내려놓고 상대방 밑으로 들어가야 한다.
기업이나 조직이 합병된다고 생각해보자. 보스가 두명일 수는 없으니까 원래 보스였던 둘 중에 합병당하는 쪽의 보스는 더이상 보스일 수 없고 인수하는 쪽 보스의 부하로 들어가야 하는 것이다.
이 때 왼쪽 원소가 속한 집합 기준으로 합칠 것인지, 아니면 오른쪽 기준으로 합칠 것인지는 구현하기 나름이지만 보통 왼쪽으로 합친다.
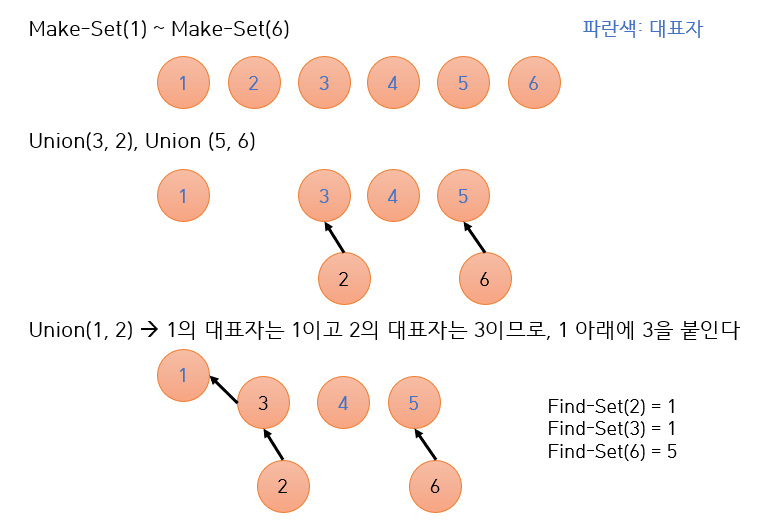
ex)
{1, 2, 3} 이란 집합이 있고 {5, 6, 7} 이란 집합이 있다.
Union(2, 7) 을 하면, 2의 대표자는 1이고 7의 대표자는 5이다.
서로 대표자가 다르기 때문에 다른 집합이며, 합칠 수 있다.
새로운 집합은 {1, 2, 3, 5, 6, 7} 이 되며 대표자는 1이다.
3. Union-Find 연산 예시
4. Union-Find 알고리즘의 구현
링크드 리스트를 이용한 구현과 트리를 이용한 구현이 있다.
> 링크드 리스트 구현: 하나의 링크드 리스트를 하나의 집합으로 보고 관리하며, 링크드 리스트의 맨 앞 원소를 대표자로 본다.
> 트리 구현: 하나의 트리를 하나의 집합으로 보고 관리하며, 트리의 루트 노드를 대표자로 본다.
링크드 리스트 구현보다는 트리 구현이 간단하기 때문에 트리로 많이 구현하는 편이다.
(링크드 리스트의 경우 다음 노드를 가리키는 링크, 대표자를 가리키는 링크를 모두 관리해야 해서 까다롭다)
트리 구현이라고 하면 뭔가 트리를 표현하기 위한 Class를 만들어야 한다던가 그런 생각이 들 수도 있는데, 사실 그럴 필요도 없고 실질적으로는 배열을 이용해서 쉽게 구현할 수 있다. 아래 그림을 보자.

예를 들어 2번 노드의 경우, parents[2] = 3이므로 3번 노드가 부모이다.
3번 노드를 찾아가보면 parents[3] = 1이므로 1번 노드가 부모이며,
2번 노드를 찾아가보면 parents[1] = 1인데 자기 자신이 부모라는 것은 루트 노드라는 뜻이므로 1번이 대표자이다.
배열의 값이 부모 노드를 가리키게 하여, 값을 따라가다보면 루트 노드를 찾아낼 수 있다는 점에서 논리적으로 트리라는 것이다.
그러면 2번에서 살펴본 각 연산들을 구현한 Java 코드를 보자.
1) Make-Set
int[] uf_parents = new int[N];
for (int i=0; i<N; i++) {
uf_parents[i] = i;원소가 0번부터 N-1번까지 총 N개 있다고 가정했을 때 이렇게 만든다.
초기 상태에서는 모든 원소의 대표자는 자기 자신이다.
사실 Make-Set의 경우 굳이 함수를 따로 빼거나 할 필요도 없어서 이게 연산이라는 것도 인식하기가 힘들다. 그냥 parents 배열을 만드는 것 자체가 Make-Set인 것이다.
2) Find-Set
private static int find_set(int a) {
if (uf_parents[a] == a) { // 대표자를 찾았으면
return a;
}
else { // 대표자를 못 찾았으면, 재귀적으로 계속 부모노드를 타고 올라간다
return find_set(uf_parents[a]);
}
}대표자를 찾을 때까지 재귀함수를 타서, 최종적으로는 대표자의 번호가 리턴된다.
3) Union
private static boolean union(int a, int b) {
int a_root = find_set(a);
int b_root = find_set(b);
if (a_root != b_root) { // 대표자가 다르면, 합친다
uf_parents[b_root] = a_root; // (b의 대표자) 의 대표자를 (a의 대표자) 로 만든다
return true;
}
else { // 대표자가 같으면 이미 같은 집합이므로 의미 X
return false;
}
}보통 리턴타입을 boolean 타입으로 지정해서, Union 성공 또는 실패 여부를 리턴하게 한다.
Find-Set을 해서 이미 같은 집합에 속해있다면, 그냥 아무것도 하지 않으며 그 표시로 false를 리턴한다.
서로 다른 집합에 속해있다면 합치는데, b의 대표자를 a의 대표자 밑에 갖다 붙인다. 그러면 b에서 타고 올라가다보면 a의 대표자가 나오게 되므로 a와 b가 같은 집합에 속하게 된 것이다.
* 참고: 여기서는 '인덱스 = 값' 인 경우를 루트 노드 (대표자) 로 식별했는데, 꼭 그렇게 만들 필요는 없다. 0이라던지 음수 같이 원소를 의미하지 않는 다른 숫자를 줘도 되며, 그 경우 그런 숫자가 나왔을 때 대표자라고 인식하게 하면 된다.
루트 노드 값으로 음수를 주면 '자신이 포함하고 있는 원소들의 수' 와 같이 뭔가 다른 정보를 표현하게 만들 수도 있다. 이 경우, parents[3] = -4이면 일단 음수값이므로 3이 대표자이며, 3이 이끄는 집합이 가지고 있는 원소가 4개라는 의미가 된다.
5. 문제점과 해결방법: 랭크, 패스 압축
위의 기본 Union 연산을 하다보면 생기는 문제점이 있다. 바로 트리의 depth와 관련된 문제이다.
Union(x, y) 를 할 때, x가 속한 집합이 큰 트리 (depth가 깊은 트리) 고 y가 속한 집합이 작은 트리면 별 문제가 없다. y쪽 집합을 x의 '대표자 바로 밑에' 붙이기 때문에 depth가 쓸데없이 깊어지지 않는다.
그런데 반대로 y쪽이 큰 트리라면?

최악의 경우 그림과 같이 원소의 수 = depth인 편향 트리가 되어버릴 수도 있다. 이렇게 되면 뭐가 문제냐면, 트리 깊은 곳에 있는 원소에 대고 Find-Set을 호출하면 대표자까지 타고 올라가는데 시간이 오래 걸린다는 것이다.
그림에서 Find-Set(4) 를 호출하면 대표자를 찾기 위해서 재귀함수를 4번이나 타야 한다.
(반대로 Union(4, 5) 로 호출했다면 5번이 1번 밑에 붙으면서 트리의 depth가 더 늘어나지 않았을 것이다)
트리를 이용하는 중요한 이유 중 하나가 빠른 탐색 속도인데 (예를 들어 완전 이진 트리에서 바닥에서 루트까지 타고 올라가는데 걸리는 시간은 logN. 힙 정렬 등 여러 사례가 있다) 저렇게 일자로 쭉 뻗어버리면 그냥 선형 리스트를 쓰는 것과 다름없는 N만큼의 시간이 걸리게 된다.
이 문제를 해결하기 위해 고안된 두 가지 방법이 있다.
1) 랭크 (Rank) 를 이용
위에서 '큰 트리 밑에 작은 트리를 붙이면 큰 문제가 없다' 라고 얘기했는데, 기존에는 어떤게 큰 트리고 어떤게 작은 트리인지 식별할 방법이 없었다.
그럼 트리의 depth를 어디다 저장해놓으면 되지 않을까? 라고 할 수 있겠다. 그걸 Rank라고 부른다.
그러니까, 각 트리의 depth (Rank) 를 저장해놓은 다음 Union을 할 때 Rank가 낮은 트리를 Rank가 높은 트리 밑에 붙이자는 아이디어다.
그러나 이 방법은, 아예 한 트리가 완전 깊은 편향 트리이고 한 트리는 작은 트리인 경우엔 쓸모가 있지만, 두 트리의 depth가 비슷한 경우에는 별로 쓸모가 없다.
그런 경우엔 Rank를 쓰나 안 쓰나 어차피 비슷하게 합쳐질 것이고, 합치고 보니 Rank가 늘어나기도 한다.
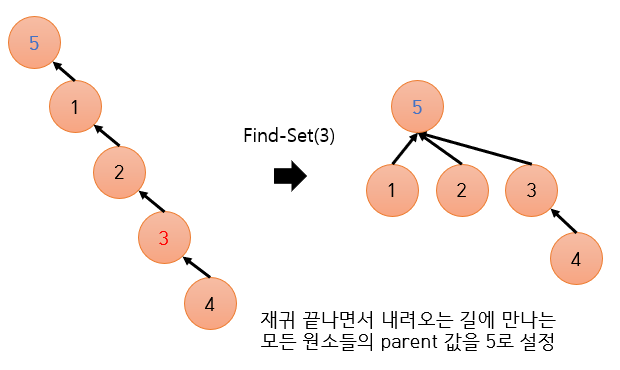
2) 패스 압축 (Path Compression)
위 그림과 같이 Find-Set을 하면서 만나는 노드들을 다 대표자 밑에 갖다 붙여버린다.
Union-Find 알고리즘에서 트리를 사용하는 것은 오직 대표자를 찾기 위함이므로, 루트 노드만 빨리 찾으면 장땡이다. 그러니 루트 노드 바로 밑에 달려있는 자식 노드가 많은 것은 문제가 되지 않으며, 트리를 좌우로 넓게 만드는 대신 depth를 줄이면 이득인 것이다.
구현은 너무나도 간단하다. Find-Set에서 return을 할 때마다, 리턴하기 전에 자기 자신의 parents 값을 리턴값 (=대표자) 으로 바꿔버리면 된다.
private static int find_set(int a) {
if (uf_parents[a] == a) {
return a;
}
else {
return uf_parents[a] = find_set(uf_parents[a]);
}
}단, 패스 압축은 Find-Set을 호출할 때만 이루어지며 Find-Set의 출발점부터 시작해서 타고 올라가는 과정에서 동작하는 것이기 때문에, Find-Set이 호출되는 지점보다 더 깊은 곳에서는 패스 압축이 일어나지 않는다는 한계가 있다.