
티스토리 뷰
---
1. 서버리스 컴퓨팅 (Serverless Computing)
전통적으로 웹 기반으로 서비스를 만든다고 하면 클라이언트와 서버, 즉 프론트엔드와 백엔드를 각각 다루게 된다. 그 중에서도 서버 쪽을 보면, 물론 서버 사이드 프로그래밍 언어를 이용해 서비스를 만드는 것도 중요하지만 '서버 컴퓨터' 의 환경을 구축하는 것도 일이다.
가장 기본적인 클라이언트-서버 구조로 만들었던 최근 프로젝트를 예시로 들면, 서버로 쓰기 위해 AWS EC2에서 가상 머신을 만들었으며 거기에 접속해서 Apache 웹 서버랑 Tomcat, MySQL을 설치했다. 그리고 이런 서버 소프트웨어들의 설정이라던지 환경 변수라던지... '코드' 이외에도 신경써줘야 할 것들이 많다. 이러한 서버 환경 준비 작업들을 전문용어로 프로비저닝 (Provisioning) 이라 부르기도 한다.
서버리스 컴퓨팅이란 이러한 서버 관리 작업들을 직접 할 필요 없이, 코드만 올려서 실행할 수 있다는 컴퓨팅 개념 또는 그러한 서비스를 말한다.
Server-less라는 단어를 그대로 해석하면 '서버가 없다' 는 말인데, 서버 컴퓨터가 없는데 서비스가 동작하는 마법같은 일이 가능하다는 것일까? 사실은 정확히 말하면 서버의 실체가 존재하지 않는다는 말이 아니라 서버가 외부 서비스 -즉, 클라우드 서비스- 에 의해서 자동으로 관리되므로 사용자 (개발자) 가 직접 신경쓸 필요가 없다는 뜻이다. 다시 말하면 사용자 입장에서는 마치 '서버가 없는 것처럼 느끼게' 된다는 것이다.
---
2. 마이크로서비스 (Microservice)
전통적인 서비스 개발 방식은, 서비스가 제공하는 모든 기능을 하나의 애플리케이션에 담아서 배포하는 방식이다. 이러한 서비스를 모놀리식 (Monolithic) 구조라고 하는데, 이러한 모놀리식 구조는 가장 보편적으로 사용되어왔던 방식이지만 최근 들어 다음과 같은 단점이 부각되기 시작했다.
- 확장성이 낮음: 서비스 내의 각 기능들이 긴밀하게 연결되어 있고 의존성을 가지므로 새로운 기능을 추가하거나 기존의 기능이 수정될 때 다른 부분까지 손봐야 하는 경우가 많다. = 개발자가 내 기능을 수정하기 위해 다른 부분까지 다 알아야 한다.
- 긴 배포 시간: 한번에 모든 기능이 담겨있는 애플리케이션을 통째로 배포하므로 배포 시간이 길다.
객체지향을 공부했다면 클래스나 함수를 만들 때, 하나의 클래스나 함수에 모든 로직을 때려박는게 아니라 기능별로 적절하게 나누어야 한다는 내용을 들어봤을 것이다 (실제로 개발할 때 지키긴 참 어렵지만...). 이런 걸 모듈화라고 하고, 모듈화가 잘 되어있으면 High-Cohesion & Low-Coupling을 가진다고 말한다.
Cohesion이란 하나의 모듈 안에 들어있는 내용들이 얼마나 긴밀하게 연관되어 있는지, Coupling이란 서로 다른 모듈간이 상호간에 의존하는 정도를 의미한다. 즉 잘 만들어진 프로그램 = High-Cohesion & Low-Coupling = 하나의 모듈은 하나의 기능만 하고 다른 모듈과는 독립적으로 동작하는 것이다.
마이크로서비스는 이런 개념을 서비스 레벨로 끌어올린 것이라고 생각하면 편할 것 같다.
사실 이게 아직 나온지 오래되지 않은 개념이다보니 모두가 인정하는 100% 정확한 정의는 존재하지 않지만, 일반적으로 많이 언급되는 그리고 내가 AWS에서 직접 들은 마이크로서비스에 대한 정의는 대략 아래와 같다.
- 각 서비스들이 서로 네트워크를 통해 (REST) API로 통신한다.
- 서비스들은 개별적으로 업데이트될 수 있으며 서로 영향을 주지 않는다.
- 다른 서비스의 내부 구조를 알지 못해도 내 서비스의 코드를 업데이트할 수 있다.
즉 서비스들이 Loosely-Coupled 되어있는 상태로 서로 API를 이용해 통신하는 것을 의미한다는 것이다.
이런 마이크로서비스 구조를 제대로 만들면 서비스의 확장이 용이해지며, 개발자들이 자신의 책임에 집중할 수 있고, 업데이트한 서비스만 따로 배포하면 되므로 배포 시간이 짧아진다. 물론 각 서비스들이 REST API로 통신하는만큼 네트워크 이슈도 있고, 마이크로서비스에 맞는 개발 환경에 새롭게 적응해야 하는 등 무조건 좋기만 한건 아니다.
서버리스 컴퓨팅과 마이크로서비스는 별개의 개념이지만 상호보완적인 관계이기에 같이 언급될 때가 많다. 마이크로서비스의 이론을 구현하기 위해서는 서버리스가 딱이고, 실제로 AWS Lambda를 비롯해 서버리스 컴퓨팅 플랫폼이라고 나온 것들이 다 마이크로서비스 이론을 기반으로 하고 있다.
+ SOA (Service-Oriented Architecture) 와 마이크로서비스의 차이점?
마이크로서비스 이전에 (2000년대 초중반) 이미 모놀리식 구조에서 탈피하여 서비스를 분리하자는 SOA라는 이론이 이미 있었다. 마이크로서비스 아키텍처는 SOA보다 더 발전된 형태라고 할 수 있는데 사람마다 얘기가 조금씩 다르긴 하지만 보통 많이 얘기하는 건 커뮤니케이션 방식의 차이와 데이터베이스의 차이다. SOA에서는 Enterprise Data Bus라는 데이터 전송로를 두고 복잡한 프로토콜을 써서 통신했지만 마이크로서비스는 REST API로 통신하며, SOA에서는 전통적인 Centralized RDB를 사용했지만 마이크로서비스에서는 Distributed된 DB, NoSQL DB가 많이 사용된다.

3. AWS Lambda를 이용한 Serverless-based Microservice 예제
가장 널리 알려진 클라우드 서비스인 AWS의 서버리스 컴퓨팅 서비스 Lambda를 이용해서 간단한 마이크로서비스를 만드는 방법에 대해 소개한다.
예시는 위 그림과 같이 사용자가 AWS S3에 이미지 파일을 업로드하면, 그걸 AWS Rekognition (이미지 인식 서비스) 을 이용해 얼굴 인식을 한 결과를 로그로 출력하는 서비스이다.
여기서 'S3에 이미지 파일을 업로드하는 행위' 가 Lambda Function을 호출하게 되는데, 이처럼 Lambda로 만든 마이크로서비스를 호출할 수 있는 행위를 Trigger라고 한다. Lambda의 기본 개념은 '어떤 Trigger가 발생했을 때 그에 맞는 Lambda Function을 호출하여 실행하는' 것이다.
위 그림의 흐름도를 보면 AWS의 서버 컴퓨터를 제공하는 서비스인 EC2가 없다! 그러니까 서버리스인 것이다.
1) S3 버킷 준비
S3에 이미지를 업로드하는 것을 Lambda Function의 Trigger로 삼기로 했으므로 S3을 먼저 세팅해야 한다. 세팅이란게 별 건 없고 '버킷' 이라는 걸 만들어줘야 하는데 이미지를 업로드하기 위한 큰 단위, 그러니까 폴더 비슷한 거라고 생각하면 된다.
버킷을 만들었으면 처음엔 비어있을 것이다. Lambda Function을 다 만들고 나서 이따가 이 버킷 안에 이미지 파일을 업로드할 것이다.
2) IAM 권한 설정
AWS에는 수많은 서비스들이 있으며, 각 서비스마다 사용자 또는 다른 서비스로부터의 접근 권한을 설정해줄 수가 있다. 이를 IAM (Identity & Access Management) 이라 한다. IAM을 이용해서 Lambda Function이 S3이나 다른 AWS 서비스에 접근할 수 있도록 만들어줘야 한다.
서비스 > IAM > 역할 (Role) 로 들어가서 '역할 만들기' 를 선택한다. 그리고 Lambda를 사용하기 위해 역할을 설정하는 것이므로 Lambda를 선택하고 다음으로 넘어간다.

'권한 정책 연결' 에서는 Lambda를 사용하는 이 역할에 대한 각종 정책들의 리스트를 보여준다. 아까 그 그림을 참조해서 만들기로 했던 서비스를 다시 생각해보면, S3에 파일 업로드하는 게 트리거고 Rekognition이라는 서비스도 사용한다. 그리고 결과를 로그로 출력해서 확인할 수 있는 서비스로 CloudWatch라는게 있다. 이러한 서비스들이 여기서 만들 Lambda Function과 관련되어 있으므로, 이 서비스들에 대한 접근 권한을 줘야 한다.
'AmazonS3FullAccess', 'AWSLambdaFullAccess', 'AmazonRekognitionFullAccess', 'CloudWatchFullAccess' 를 찾아서 각각 체크하고 다음으로 넘어간다.
태그는 선택사항이니까 그냥 넘어가고, 적당한 역할 이름을 준 다음 완료를 누르자. 그러면 '역할' 이 하나 생성됐다. 이 역할을 Lambda Function을 만들 때 연결해줘야 한다.
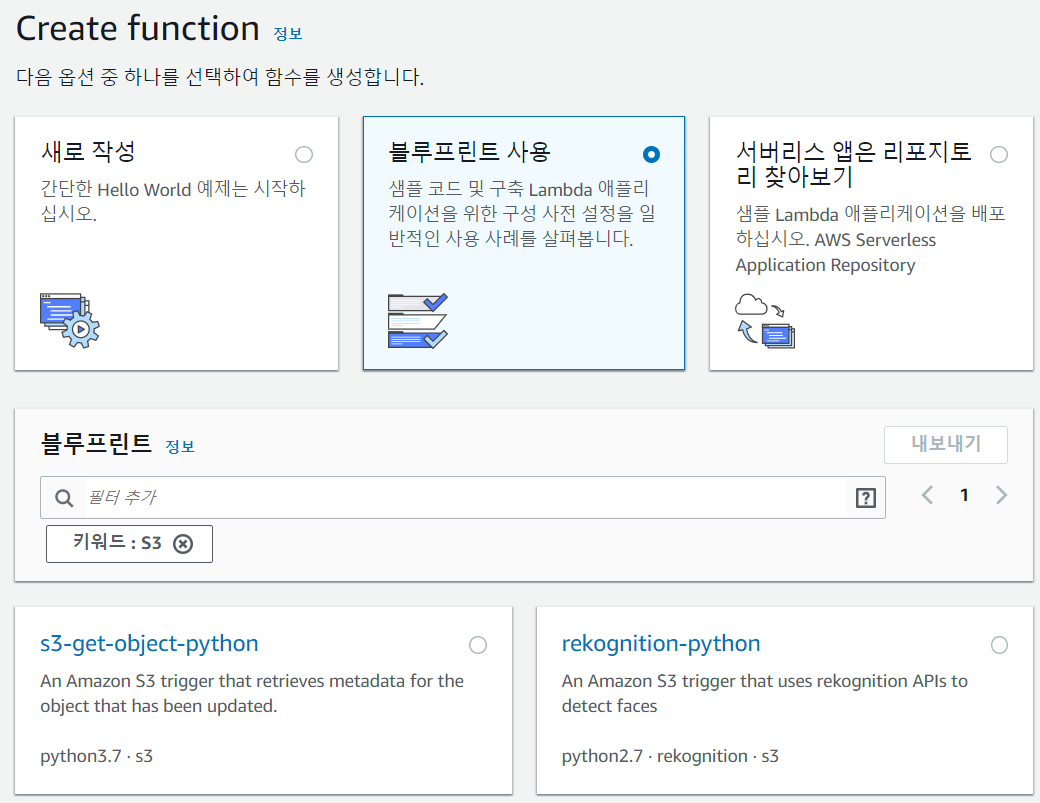
3) Lambda Function 만들기
Lambda 서비스로 넘어가서 Create Function 버튼을 누른다.
세 가지 옵션이 있는데,
- 새로 작성: 말 그대로 코드를 새로 짠다.
- 블루프린트 사용: 미리 만들어진 샘플 코드를 가져다 쓸 수 있다.
- 리포지토리 찾아보기: 써보지 않아서 정확히는 모르겠는데 AWS에서 만들어놓은 샘플 코드 말고, 다른 사람들이 올려놓은 코드를 쓸 수 있는 것 같다. github 같은 느낌으로...?
Lambda Function이란 걸 어떻게 짜야할지 아직 잘 모르기 때문에 샘플 코드, 그러니까 블루프린트를 가져다 쓰기로 하자. 블루프린트 검색에서 'S3' 이라고 쳐보면 'rekognition-python' 이라는 블루프린트가 나온다. 예제에서 한다고 했던대로 Rekognition 서비스를 이용한 얼굴 인식 결과를 출력해주는 코드이다.

다음 화면의 '기본 정보' 부분에서는 Lambda Function에 '역할' 을 매핑해줘야 한다. 앞에서 역할을 만들어놨었으니 '기존 역할 사용' 을 선택하고, 앞에서 만들었던 역할의 이름을 선택하면 된다.
'S3 트리거' 부분에서는 어떤 버킷에서 어떤 이벤트 (행위) 가 일어났을 때 Lambda Function을 호출할 것인지를 결정한다. 앞에서 만들었던 버킷을 선택하고, 이벤트 유형은 파일이 업로드됐을 때 실행할 것이므로 '모든 객체 생성 이벤트' 로 선택한다. 선택지를 보면 '파일이 삭제됐을 때' 나 'Glacier (AWS의 백업용 스토리지 서비스) 에서 파일이 복원됐을 때' 같은 이벤트를 트리거로 설정할 수도 있는 것 같다.
'트리거 활성화' 체크박스에 체크를 하고 아래로 내려가자.
아래로 내려가면 Lambda Function 코드가 있다. '새로 작성' 을 했다면 여기서 직접 코딩을 해야 했겠지만 블루프린트를 가져왔기 때문에 이미 코드가 들어있다. 그 코드를 잠깐 살펴보자.
from __future__ import print_function
import boto3
from decimal import Decimal
import json
import urllib
print('Loading function')
rekognition = boto3.client('rekognition')
# --------------- Helper Functions to call Rekognition APIs ------------------
def detect_faces(bucket, key):
response = rekognition.detect_faces(Image={"S3Object": {"Bucket": bucket, "Name": key}})
return response
def detect_labels(bucket, key):
response = rekognition.detect_labels(Image={"S3Object": {"Bucket": bucket, "Name": key}})
# Sample code to write response to DynamoDB table 'MyTable' with 'PK' as Primary Key.
# Note: role used for executing this Lambda function should have write access to the table.
#table = boto3.resource('dynamodb').Table('MyTable')
#labels = [{'Confidence': Decimal(str(label_prediction['Confidence'])), 'Name': label_prediction['Name']} for label_prediction in response['Labels']]
#table.put_item(Item={'PK': key, 'Labels': labels})
return response
def index_faces(bucket, key):
# Note: Collection has to be created upfront. Use CreateCollection API to create a collecion.
#rekognition.create_collection(CollectionId='BLUEPRINT_COLLECTION')
response = rekognition.index_faces(Image={"S3Object": {"Bucket": bucket, "Name": key}}, CollectionId="BLUEPRINT_COLLECTION")
return response
# --------------- Main handler ------------------
def lambda_handler(event, context):
'''Demonstrates S3 trigger that uses
Rekognition APIs to detect faces, labels and index faces in S3 Object.
'''
#print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key'].encode('utf8'))
try:
# Calls rekognition DetectFaces API to detect faces in S3 object
response = detect_faces(bucket, key)
# Calls rekognition DetectLabels API to detect labels in S3 object
#response = detect_labels(bucket, key)
# Calls rekognition IndexFaces API to detect faces in S3 object and index faces into specified collection
#response = index_faces(bucket, key)
# Print response to console.
print(response)
return response
except Exception as e:
print(e)
print("Error processing object {} from bucket {}. ".format(key, bucket) +
"Make sure your object and bucket exist and your bucket is in the same region as this function.")
raise e
일단 boto3이라는 낯선 라이브러리가 들어가는데 이건 AWS API들이 포함된 파이썬 라이브러리 (즉 SDK) 다.
Helper Function 어쩌구 부분은 boto3을 이용해서 Rekognition API를 호출하는 부분이다.
중요한건 그 밑에 나오는 'lambda_handler' 함수인데 얘가 바로 '핸들러 함수' 라는 것으로 앞에서 설정해둔 트리거에 의해 호출되는 함수를 말한다. 핸들러 함수의 이름은 바뀔 수도 있지만 'event', 'context' 라는 두 개의 파라미터는 꼭 존재해야 하는데 각각에 대한 설명은 아래와 같다.
- event: 트리거를 발생시킨 서비스로부터 넘어오는 정보들이다. 어떤 서비스인지에 따라 형식이 다르며, 예를 들어 S3으로부터 호출됐다면 이 'event' 안에 업로드된 파일에 대한 정보 등이 담겨있는 것이다.
- context: 함수의 이름이나 식별자, 버전, 할당된 메모리 양 등 실행 환경에 대한 정보들이 담겨있다. 예제 코드에선 쓰지 않았다.
아래 코드를 더 보면 이미지 인식을 하기 위해서는 Rekognition API에게 bucket이랑 key (파일에 대한 식별자인 듯) 정보를 줘야 하는데, 이걸 event 객체를 뜯어서 얻어내야 한다. 이 event라는 객체의 정체는 JSON으로, Python에서는 dictionary 타입이다. 그러니까 dictionary의 내용에 접근하기 위한 방법을 쓰면 된다.
4) 테스트
S3에 사람 얼굴이 나와있는 적당한 사진 파일을 하나 업로드한 다음 CloudWatch > '로그' 로 들어가보면 위에서 만든 람다 함수의 이름을 볼 수 있다. 눌러서 사진 파일을 올린 시간에 해당하는 '로그 스트림' 을 클릭해보면 로그를 볼 수 있는데, 여기서 'FaceDetails: ...' 로 시작하는 긴 텍스트를 확인할 수 있다면 성공한 것이다.
보통 얼굴 인식이라고 하면 성별이라던지 나이, 표정 분석 같은걸 많이 생각하는데 그런 정보는 안 나오고 좌표값만 잔뜩 나와서 의아할 수 있다. 근데 detect_faces 메서드의 기본 설정이 그렇고, 메서드에 인자로 Attributes=["ALL"] 을 주면 추가적인 정보까지 확인할 수 있다.